



新闻中心
时间:2021-10-27 15:48:55 次数:3911
技术背景
大数据时代的到来,数据正以前所未有的速度爆发性增长,数据已经成为土地、能源等传统资源之外的一种新资源。大量的数据来自不同的源头,杂乱无章,质量参差不齐。一般单位少则十几个信息系统,多则几十上百个,这些系统之间若沟通不畅,会产生数据孤岛,造成工作效率低下。一方面大量数据闲置,无法有效被利用,另一方面数据被重复录入,费时费力,容易产生差错。

只有可管理,可调用,可计算,可变现的数据资源才能成为资产,才能服务政府,城市和产业,帮助实时统筹科学决策。正确决策来源于对实际情况的了解,某种意义上说,就是对来自各方的各类数据的正确汇集、整理、归纳、分析,从而得出正确的结论。
数据集成是把不同来源、格式、特点性质的数据在逻辑上或物理上有机地集中,通过应用间的数据交换从而达到集成,解决数据的分布性和异构性的问题,从而为企业提供全面的数据共享。
产品简介
威廉希尔中文网站大数据集成系统是一款基于分布式并行计算架构开发的ETL数据集成系统。采用组件化设计,适配混合主流云,提供多种类型的数据抽取、整合插件、监控组件、作业流程模型,支持快速定制插件开发,具备高吞吐、高可用、高扩展特性,为海量数据的超大规模数据仓库建设提供抽取、整合、清洗、入库等集成业务。
技术架构
系统主要包含配置管理、任务调度、监控中心、元数据管理等
运行架构
系统运行具有高可用的特性,会自动感知执行引擎异常,将异常设备的任务转发到正常设备上重新执行。运行架构如下图:
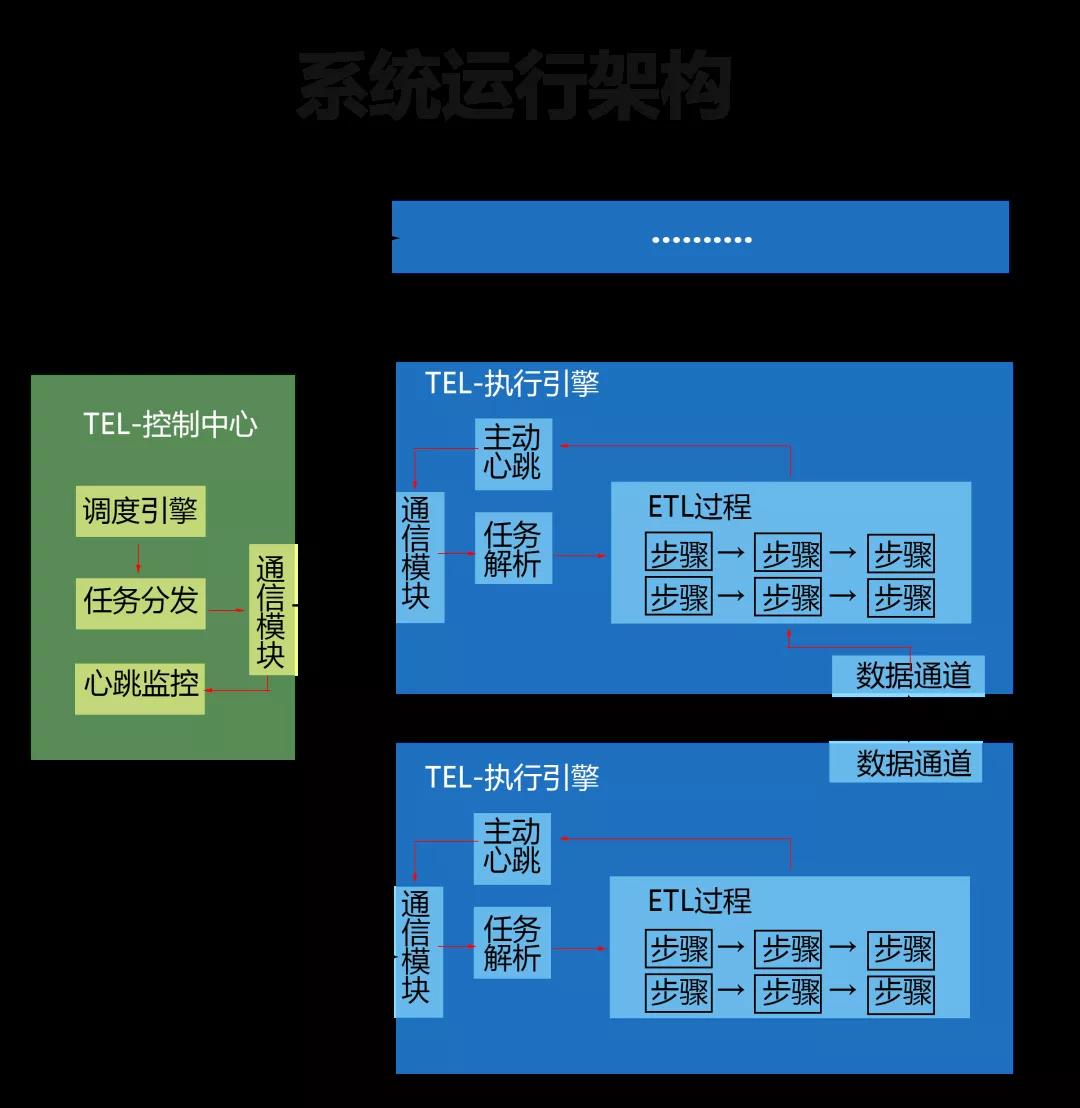
部署架构
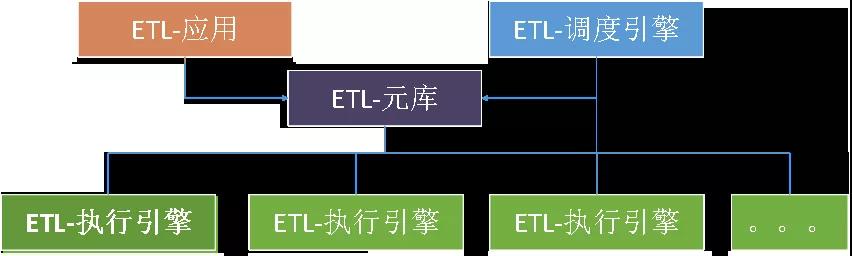
系统部署包含应用端、调度引擎、执行引擎。
ETL-应用: 完成数据集成逻辑的工作流建模和日常监控管理。
ETL调度引擎:统一执行逻辑的调度控制和任务分发,分布式管理。
ETL-执行引擎:ETL任务的具体执行器。
部署架构如下图所示:
产品优势
■高吞吐处理能力:采用多线程处理算法,高效的内存利用率;任务运行过程无需本地磁盘IO操作,提升整体单位时间的大批量处理能力;支持TB/h级的大数据集成业务性能。
■高扩展、高可靠:并行架构提升单机处理能力的线性扩展;新增执行引擎的快速部署和自动识别,分布式架构提升多机处理能力的线性扩展;执行引擎宕机的自动识别和任务转移,保证任务的顺利执行。
■可视化流程配置:通过简单的图形拖拽配置数据集成流程,简单易用的专业化配置。
■集成业务全流程监控:可对处理过程的每个步骤,每个子流程处理进行实时监控,简单快速发现处理过程遇到的漏数据,错处理等问题。
■统一的元数据模型:基于统一公共仓库元模型,可与产品线其他产品无缝对接,简化整体解决方案的实施运维。
■大数据技术支持:支持主流的关系型数据库,NOSQL数据库,全文库处理等主流大数据产品的抽取入库,以及异构库之间的抽取入库。
■低廉的硬件成本:使用x86架构的PCServer,无需昂贵的unix服务器。
■数据源支持:支持超过40+数据源的链接包括国产数据库。
■业务规则支持:支持自定义数据检查规则、质量规则、补全规则等,可以实现复杂的数据集成需求。
■处理模式:支持批流一体化处理,大幅提升数据的采集和同步时间。
■快速扩展支持:提供插件开发SDK,可快速定制开发所需的业务插件。
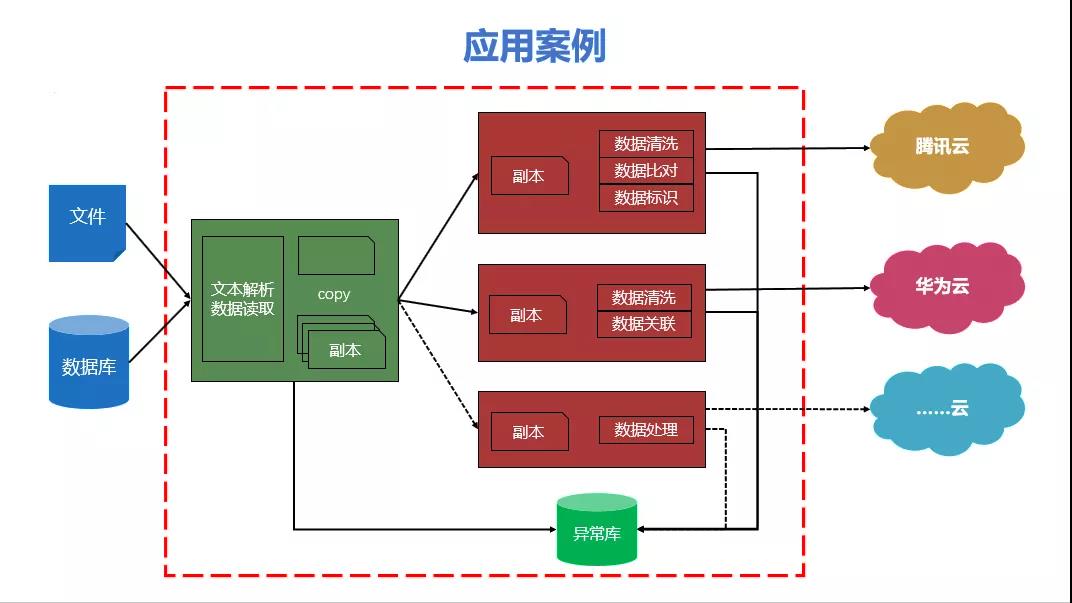
1、系统在某地配置管理2000余个大数据治理作业,支撑日增量百亿级别的数据抽取、整合、清洗、转换、入库等集成业务,运行稳定。
2、系统在多地已经分别与华为云、腾讯云、华三云、阿里云,甚至是一地多云进行适配对接,完成数据的抽取、整合、清洗、转换,入库等集成业务。



威廉希尔中文网站公众号
 闽公安备案:35021102000930号
闽公安备案:35021102000930号






